
Themen, Foren oder Schlüsselwörter?
Wie schon erwähnt können im Heise Newsticker verschiedene Kategorisierungen für weitere Analysen verwendet werden:
- "weiterführende Themen" wird es unten einem Artikel genannt und enthält eine unterschiedliche Anzahl an Links zu Bereichen, unter denen weitere (ältere) Artikel mit ähnlichem Schwerpunkt zu finden sind. Grundsätzlich wäre dies eine gute Kategorisierung von Artikeln, aber leider gibt es eine deutliche Zahl von Artikeln, die ganz ohne Thema geführt werden, was diese "Themen" dafür eher ungeeignet macht.
- "Foren" tauchen ebenfalls unten einem Artikel auf und führen per Link zu einem Userforum eines speziellen Themas. Dies könnte man als Kategorie für einen Artikel verwenden, aber leider gilt auch hier, dass bei weitem nicht alle Artikel einen solchen Link enthalten und damit aus der Statistik fallen würden.
- "Keyword" werden nicht im sichtbaren Teil eines Artikels geführt, sondern als meta-Tag im HTML-Code. Diese werden für die überwiegende Zahl der Artikel geführt und bieten sich daher zur weiteren Analyse an.
Entsprechend werden wir im folgenden näher auf die Schlüsselwörter eingehen und sehen, was sie uns über die Artikel, die Redakteure und die Redaktion verraten. Im Datensatz befinden sich insgesamt 19092 unterschiedlichen Keywords, von denen aber über 11000 Keywords für die Analyse von Artikeln wenig zu gebrauchen sind, da sie nur 1x Verwendung finden. Knapp 1100 Keywords werden mehr als 10x in Artikeln verwendet und nur diese 105 Keywords werden mehr als 100x verwendet:

Erstaunlich: es erscheint so, als wäre iMac die Hauptzeitschrift des heise-Verlags: "Apple" ist das mit Abstand am häufigsten verwendete Keyword im Newsticker; gefolgt von "Datenschutz", "Google", "Netze" und "Spiele". Bei näherer Betrachtung lässt sich die Präsenz von "Apple" aber gut erklären und relativieren: Jede Meldung zu iPhone, zu MacBook, zu iTunes oder IOS wird mit diesem Keyword bedacht und ist damit 4 Keywords in einem. Nimmt mal "Apple" aus der Statistik raus, passt das Bild wieder der Schlüsselwörter wieder.

Die Redakteure der Heise-Redaktion
Es gibt viele Möglichkeiten, die Verteilung von Artikeln je Autor zu visualisieren; am besten gehällt mir aber doch noch die WordCloud: Begriffe werden proportional zur Anzahl ihrer Vorkommnisse in der Datenbasis in verschiedenen Größen dargestellt. In diesem Fall habe ich die 30 am häufigsten auftretenden Autoren-Namen nach Anzahl ihrer Artikel skaliert:

Schwer zu übersehen: Andreas Wilkens zeichnet gemeinsam mit Martin Holland mit gut 4000 Aritkeln für den größten Teil der veröffentlichten Nachrichten verantwortlich; zumindest soweit sich dies aus der Angabe jeweils unter einem Artikel ergibt. Und mit Kristina Beer, Axel Kannenberg, Daniel Berger, Daniel Herbig, Volker Briegleb, Fabian A. Scherschel und auch Dr. Volker Zota sind auch alle anderen, laut c't-Impressum für die Online-Redaktion eingeteilte Redakteure in verschiedenen Anteilen vetreten.
Insgesamt meldet die Datenbank 133 verschiedene Autoren für den Zeitraum von Anfang 2016 bis September 2017; 38 davon haben in dieser Zeit jeweils mehr als 100 Artikel veröffentlicht.

Verarbeitung, Visualisierung und erste Überraschungen
Schon mit den ersten Daten, die in die Datenbank fließen, muss geklärt werden: wie und womit sollen die Daten eigentlich analysiert und visualisiert werden? Die von David Kriesel genutzte Software Tableau kommt eher nicht in Frage. Sie ist zwar mächtig, für ein Privat-Projekt aber dann doch nicht im richtigen Preisrahmen. Auch andere Tools zeichnen sich durch mächtige Funktionen aus, haben aber Linzenzkosten, die zumindest für einen allerersten Blick in DataSience nicht die erste Wahl sind. An freier Software gibt es z.B. FnordMetric, bei dem ich allerdings mit dem Datenimport aus der MySQL-DB nicht klar gekommen bin, oder das gute alte R. Hier habe ich mich ein wenig drin versucht, aber neben der Kommadozeilen-Komplexität stellte auch hier die Arbeit mit den SQL-Daten eine Hürde da.
Schließlich bin ich bei ElasiticSearch und Kibana gelandet. Die Elastic-Suite ist ebenfalls sehr mächtig und darüber hinaus OpenSouce. Nach erster Skepsis zeigt sich schnell, dass zumindest die vorrangigen Fragen schnell, einfach und optisch ansprechend beantwortet werden können. Gesagt, getan: Die gecrawlten Daten landen -- leicht aufbereitet -- in einem ElasticSearch-Index und können fortan mit Kibana sehr einfach analysiert werden. Zum Beispiel die Betrachtung der Anzahl der Artikel pro Wochentag und Stunde:
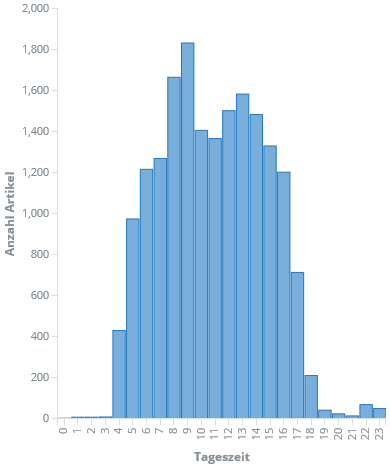
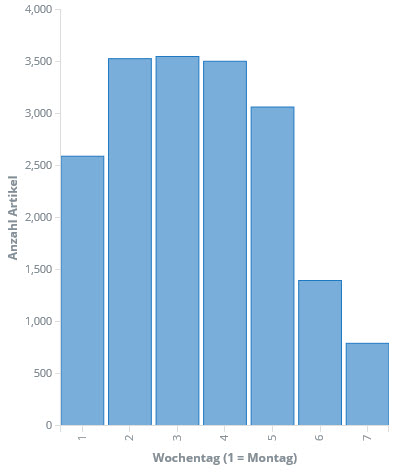
Man kann schon erkennen: Ab vier Uhr morgens geht es los und zwischen 17:00 und 18:00 ist Feierabend für die meisten. Auch die Verteilung über die Woche ist erwartungsgemäß. Überraschend ist vielleicht, dass die Woche doch eher verhalten beginnt.
Womit kann ich arbeiten?
Der Entschluss ist gefasst: Der Heise-Newsticker will analysiert werden. Also ran an die Daten.
Betrachet man eine typische HeiseNews-Seite, so lassen sich zunächst ein paar klassiche Informationen für die spätere Analyse finden:
- Titel
- Datum/Uhrzeit der (ersten) Erstellung
- Author
- Anzahl Worte
- Anzahl enthaltener Links
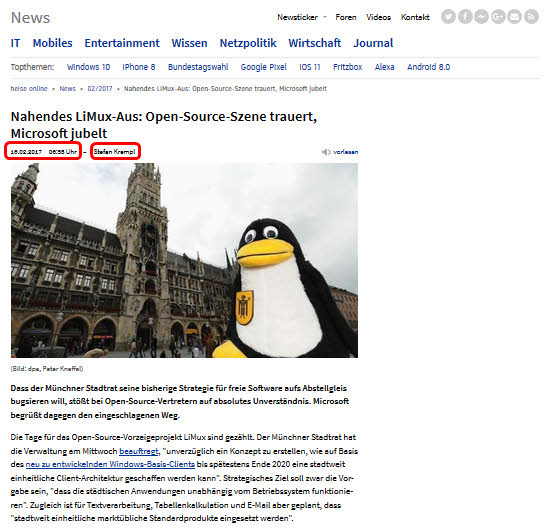
Damit könnten wir vermutlich eine erste Statistik aufsetzen, allerdings fehlt es noch an einer Kategorisierung der Nachrichten für schicke Grafiken und Korrelationen. Hierfür bieten sich bei heise.de mehrere Informationen der Webseite an:
Dezember 2016 - DataMining ist absolut faszinierend
Es ist Tag 2 des 33C3 und ich sitze in Saal 2. Gerade habe ich meine ersten Erfahrungen im Sub-tiltlen gesammelt und lausche nun dem Talk von David Kriesel "SpiegelMining": Öffentlich verfügbare Daten einfach mal tiefer analysieren und neue Schlüsse daraus ziehen. Ich bin absolut fasziniert von den Möglichkeiten und begeistert von den Techniken und Tools. Schnell reift der Gedanke: "das will ich auch!"
Stellt sich nur die Frage: woher kommen die Daten?
Einfach ebenfalls auf SpiegelOnline setzen wäre nicht das Richtige. Und erst ein Jahr Daten aufzeichnen zu müssen, bis es richtig losgehen kann, dauert mir irgendwie zu lange; da würde ich schon gerne direkt durchstarten. Also müssten es schon vorhandene Daten aus einem Archiv sein.
- Aktuelle Seite:
-
Startseite

- HeiseMining