
Verarbeitung, Visualisierung und erste Überraschungen
Schon mit den ersten Daten, die in die Datenbank fließen, muss geklärt werden: wie und womit sollen die Daten eigentlich analysiert und visualisiert werden? Die von David Kriesel genutzte Software Tableau kommt eher nicht in Frage. Sie ist zwar mächtig, für ein Privat-Projekt aber dann doch nicht im richtigen Preisrahmen. Auch andere Tools zeichnen sich durch mächtige Funktionen aus, haben aber Linzenzkosten, die zumindest für einen allerersten Blick in DataSience nicht die erste Wahl sind. An freier Software gibt es z.B. FnordMetric, bei dem ich allerdings mit dem Datenimport aus der MySQL-DB nicht klar gekommen bin, oder das gute alte R. Hier habe ich mich ein wenig drin versucht, aber neben der Kommadozeilen-Komplexität stellte auch hier die Arbeit mit den SQL-Daten eine Hürde da.
Schließlich bin ich bei ElasiticSearch und Kibana gelandet. Die Elastic-Suite ist ebenfalls sehr mächtig und darüber hinaus OpenSouce. Nach erster Skepsis zeigt sich schnell, dass zumindest die vorrangigen Fragen schnell, einfach und optisch ansprechend beantwortet werden können. Gesagt, getan: Die gecrawlten Daten landen -- leicht aufbereitet -- in einem ElasticSearch-Index und können fortan mit Kibana sehr einfach analysiert werden. Zum Beispiel die Betrachtung der Anzahl der Artikel pro Wochentag und Stunde:
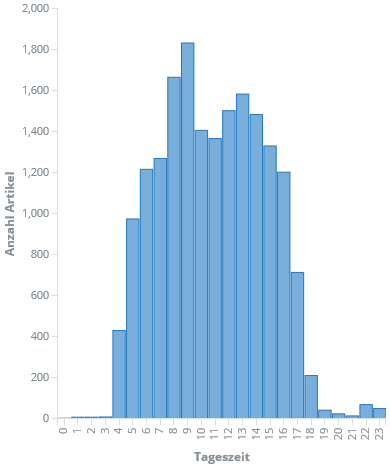
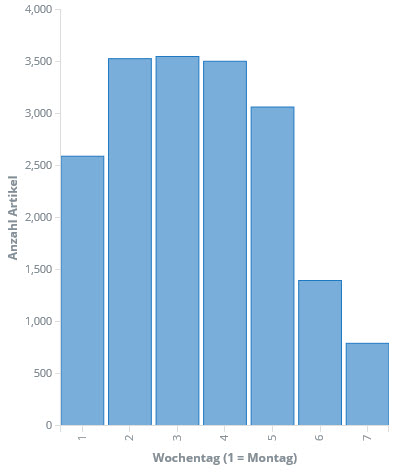
Man kann schon erkennen: Ab vier Uhr morgens geht es los und zwischen 17:00 und 18:00 ist Feierabend für die meisten. Auch die Verteilung über die Woche ist erwartungsgemäß. Überraschend ist vielleicht, dass die Woche doch eher verhalten beginnt.
Vielleicht bringt die Darstellung als Heatmap mehr Einblick:

Auf der x-Achse sind die Wochentage aufgetragen, auf der y-Achse die Stunden des Tages. Die Färbung jeden Rechtecks spiegelt die Anzahl der Artikel wieder, die an diesem Wochentag zu dieser Stunde veröffentlicht wurden. Auch hier lässt sich erkennen: Der Montag ist etwas "dünner" mit Artikeln besetzt und fängt später an. Wobei: 6 Uhr morgens ist nicht wirklich spät :-) In diesen Diagrammen sind alle Artikel enthalten, die zwischen 1.1.2016 und 30.9.2017 erschienen sind und im Archiv von heise.de gelistet wurden -- in Summe exakt 18661.
In einem nächsten Schritt können wir überprüfen, wie sich das "Zeitverhalten" der Artikelveröffentlichung über die Monate darstellt, um zu sehen, ob eine solche Heatmap repräsentativ für den gesamten Zeitraum ist. Die Grafik fördert eine Überraschung zutage:

Dargestellt ist auf der y-Achse wieder die Tageszeit, auf der x-Achse dagegen nun die Zeit von Januar 2016 bis "heute". Jedes Rechteck stellt die Summe aller Artikel dar, die in einer Woche zu dieser Uhrzeit veröffentlicht wurden. Insgesamt kann man sagen: "ja, passt!". Die Zeitspanne 05:00-18:00 haben wir schon gesehen. Allerdings ... es fallen leicht verschobene Perioden auf: von März bis Oktober nach oben und von Oktober bis März nach unten. Tja ... erwischt!
Für die Extraktion des Artikel-Zeitstempels habe ich mich für den im HTML-Code leicht zu findenden und parsenden meta-Tag entschieden. Dieser liefert aber -- wie mir nun bewusst wird -- UTC statt der lokalen Zeit, wie sie im Browser angezeigt wird. Entsprechend ergeben sich die Sprünge um 1h 2x im Jahr. Gleichzeitig sind in der Grafik alle Zeiten entsprechend 1h nach vorne verschoben, so dass wir die nominelle Arbeitszeiten in der Heise-Redation auf 06:00 bis 19:00 korrigieren müssen.
Okay: auf der einen Seite ist das blöd ... da hätte ich auch gleich drauf achten können. Also heißt es nun, ein locale() einzubauen. Auf der anderen Seite ist es sehr interessant: Obwohl der Veröffentlichungszeitunkt zunächst nichts mit Sommer- und Winterzeit zu tun hat, ist der Einfluss in den Daten zu erkennen. Oder anders formuliert: Auch wenn wir nichts über die Herkunft eines Datensatzes wüssten, wären wir ggf. allein anhand der Zeitpunkte der Sommerzeit-Wechsel in der Lage, grob auf die Ursprungsregion der Daten zu schließen.
Also gut, dann werde ich mich mal daran machen, den Zeitstempel zu korrigieren. Im nächsten Teil geht es dann weiter mit Analysen, welcher Redakteur denn so die meisten Artikel online stellt ... und zu welchen Uhrzeiten.
Update
Zwischenzeitlich konnte ich die Uhrzeiten korrigieren und nun sieht die Heatmap auch wieder ganz hübsch aus:
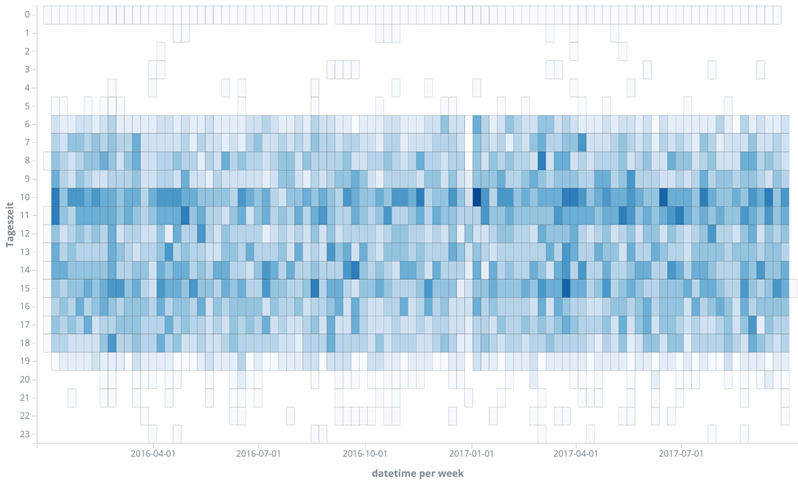
Es scheint einen gut geregelten Tagesablauf in der Heise-Redaktion zu geben: Gegen 06:00 geht es los, bis 19:00 ist üblicherweise Feierabend. Die Mittagspause ist um 12:00 und der Jahreswechsel ist heilig.
Die Konvertierung der Zeitstempel erfolgte beim Umschaufeln der Daten in die Elastic DB hinein direkt im SELECT. Für alle, die ähnliche Effekte hatten, hier das Kommando:
SELECT CONVERT_TZ(timestamp, 'GMT','MET') as timestamp FROM news;
Damit das funktioniert, muss MySQL die Timezones kennen. Falls diese noch nicht vorhanden sind, können sie (unter Linux) mit folgendem Kommando aus dem System in die MySQL übertragen werden:
# mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root --password=<xxx> mysql
Und schließlich habe ich mich in dem Zusammenhang dann gleich noch um die Umlaute gekümmert, die bis dato nicht korrekt bei Kibana angekommen sind, was für die folgenden Teile dieser Doku hinderlich gewesen wäre. Auch hier erfolgt die Konvertierung im SELECT bei der Übertragung aus MySQL heraus. Das Kommando ist etwas verschachtelt, aber äußerst wirkungsvoll:
SELECT CONVERT(CAST(author_html AS BINARY) USING utf8) as author FROM news;Damit kann es nun aber wirklich losgehen mit den nächsten Analysen!
Disclaimer
Während die Scripte laufen und Daten vom Heise-Server saugen, stellt sich mir die Frage: Wie ist das eigentlich rechtlich einzuordnen? Nun, durch die Crawler werden lediglich Daten abgerufen, die öffentlich zugänglich sind. Es findet keine Überwindung von Sperren oder Datenschutzmechanismen statt und es werden auch keine abgerufene Seiten auf andere Weise zum alternativen Abruf bereitgestellt. Weder die Nutzungsbedingungen der Onlineforen noch die Privacy Policy verbieten das automatisierte Abrufen von Artikeln oder Forenbeiträgen. Lediglich das Impressum bindet die "Vervielfältigung oder Weiterverbreitung" an die Zustimmung des Verlages; beides findet in diesem Projekt nicht statt.
Auch die demnächst hier noch zu behandelnden Analysen der Userdaten in den Artikel-Foren stellen kein rechtliches Problem dar: Schon auf heise.de werden weder in der Privacy Policy noch in den Nutzungsbedingungen der Foren solche Analysen durch den Heise-Verlag ausgeschlossen. Aber selbst wenn es einen solche Selbstverpflichtung gäbe, so hat heise.de dies nicht für externe Verarbeitung von Forendaten per Policy ausgeschlossen und auch keine technischen Maßnahmen ergriffen, die solche externen Analysen verhindern sollen. Eher im Gegenteil: Heise weist in den Privacy Policies explizit darauf hin, dass Beiträge "für jeden zugänglich sind" und auch "ohne gezielten Aufruf [...] weltweit zugreifbar" sind ... gemeint sind damit unter anderem Treffer bei Google.
Insofern: moralisch mag es zu diskutieren sein, öffentliche Daten abzusaugen und neue Informationen daraus zu desitilieren. Rechtlich erweist es sich als legitim. Und inhaltlich ist es ein Experiment zur Veranschaulichung der "Macht von Daten". Ich habe mir mit diesem Projekt zum Ziel gesetzt, die Brinsanz auszuloten, dabei aber die Privatssphäre der User zu achten. Aus diesem Grunde werden in den folgenden Analysen auch keine echten User-Namen genannt; alle aufgeführten Namen entstammen einer durch fakenamegenerator.com erzeugten Liste und sind zufällig zugewiesen.