
Die Redakteure der Heise-Redaktion
Es gibt viele Möglichkeiten, die Verteilung von Artikeln je Autor zu visualisieren; am besten gehällt mir aber doch noch die WordCloud: Begriffe werden proportional zur Anzahl ihrer Vorkommnisse in der Datenbasis in verschiedenen Größen dargestellt. In diesem Fall habe ich die 30 am häufigsten auftretenden Autoren-Namen nach Anzahl ihrer Artikel skaliert:

Schwer zu übersehen: Andreas Wilkens zeichnet gemeinsam mit Martin Holland mit gut 4000 Aritkeln für den größten Teil der veröffentlichten Nachrichten verantwortlich; zumindest soweit sich dies aus der Angabe jeweils unter einem Artikel ergibt. Und mit Kristina Beer, Axel Kannenberg, Daniel Berger, Daniel Herbig, Volker Briegleb, Fabian A. Scherschel und auch Dr. Volker Zota sind auch alle anderen, laut c't-Impressum für die Online-Redaktion eingeteilte Redakteure in verschiedenen Anteilen vetreten.
Insgesamt meldet die Datenbank 133 verschiedene Autoren für den Zeitraum von Anfang 2016 bis September 2017; 38 davon haben in dieser Zeit jeweils mehr als 100 Artikel veröffentlicht.
Für diese 38 Autoren lohnt sich ein Blick auf den Tagesablauf der Redaktion:

Hier sind nun auf der x-Achse eine Reihe von Redakteuren aufgetragen, während auf der y-Achse -- wie hier schon gewohnt -- die Uhrzeit aufgetragen ist. Je tiefer das blau in einem Feld, desto mehr Artikel hat ein Redakteur zu dieser Zeit veröffentlicht. Die beiden Top-Scorer lassen sich in dieser Grafik nicht verleugnen; die Zuordnung der weiteren Redakteure lasse ich ein wenig im Nebel. Deutlich wird aber auch so: auf den Plätzen 3 bis 7 gibt eine kleine Arbeitsteilung zwischen Früh- und Spätschicht; das sieht ein wenig nach Halbtags-Tätigkeit aus. Und auch in dieser Grafik ist ganz grob erkennbar, dass um 12:00 für die meisten Mittagspause ist.
Mengenlage
Als ein erstes Feature von Artikeln soll an dieser Stelle deren Länge herhalten. Als Maßeinheit kommen verschiedene Eigenschaften des Textes in Betracht. Für meine Auswertung habe ich mich für die Anzahl der Worte im sichtbaren Bereich des Artikels entschieden:

Der Mittelwert über alle Artikel liegt bei 373 Worten, der Median bei 314. Die meisten Artikel gibt es im Bereich zwischen 200 und 250 Worten; allein der Bereich 150-300 Worte summiert bereits 45% aller Artikel auf sich. Diese Verteilung ansich ist nicht unbedingt überraschend; entscheidende Informationen lassen sich hieraus zunächst nicht ableiten. Interessant wird es aber, wenn wir dieses Histogramm durch Überlagerung mit anderen Werten korrelieren. Als einen Vorgriff auf die detaillierte Analyse der User-Kommentare überlagern wir hier die durchschnittliche Anzahl an Kommentaren als grüne Linie:

Ganz offensichtlich steigt das Interesse der User mit zunehmender Aritkel-Länge: Während kurze Artikel bis 100 Worte im Durchschnitt 70 Kommentare bekommen, steigt dieser Wert kontinuierlich bis ca. 180 Kommentare bei Artikeln bis 600 Worte. Danach bleibt das Niveau, allerdings variiert der Durchschnittswert der User-Kommentar deutlich, was aber mit der sinkenden Datenmenge in diesem Bereich zu erklären ist. Schon interessant: Lange Artikel lesen scheint zu lohnen.
Nur aus Interesse: gibt es bei diesem Verhalten einen Unterschied zwischen den Redakteuren? Dazu schaunen wir uns eine kleine Übersicht mit den Top-6-Artikel-Autoren an:
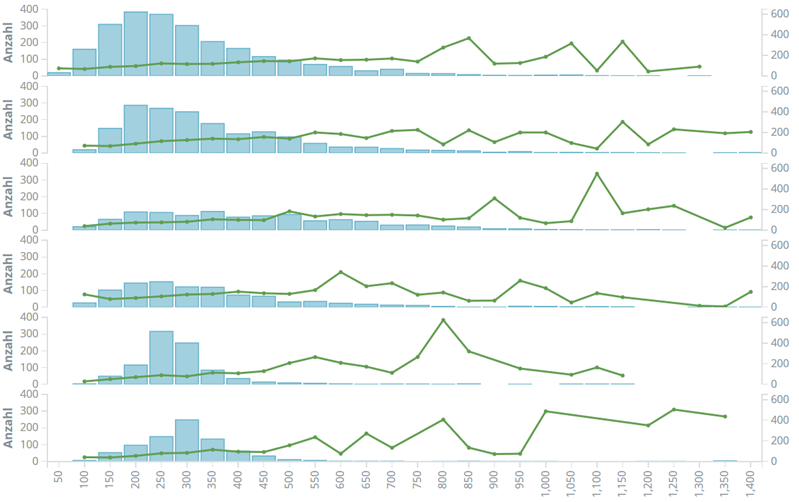
Aufgetragen sind hier wieder das Histogramm der Artikel-Mengen je Wort-Anzahlen zusammen mit den jeweils durchschnittlichen Kommentar-Anzahlen. Bei allen 6 betrachteten Autoren ist eine ähnliche Interesse-Steigung über Wort-Anzahlen zu erkennen; also kaum Unterschiede zwischen den Autoren. Spannender ist hier schon eher die Verteilung der Wort-Mengen: verschiedene Maxima, verschiedene Breiten, verschiedene Mengen. Wollte man ein Fingerprinting für Redakteure starten, wäre dies bei ausreichender Datenbasis (z.B. 6 Monate) mit Histogrammbreite und Artikel-Anzahl als erste Komponenten bereits möglich.
Keyword-Jongleure
Als weiterer Vorgriff hier noch ein erster Blick auf das Thema Keywords:

Dieses Histogramm stellt dar, wie viele Artikel mit den jeweiligen Anzahlen an Keywords versehen wurden. Offensichtlich sind für die meisten Artikel 4 Keywords vergeben worden, aber es gibt auch einige wenige Artikel mit mehr als 10 Keywords, sowie ein paar ganz komplett ohne Keywords. Beide Extreme wären nach meinem Verständnis für die Kategorisierung nicht wirklich sinnvoll, aber wie wir sehen, kommt es dennoch vor.
Wir könnten jetzt nachschauen, welcher Autor für z.B. die Null-Keyword-Artikel rausgelassen hat. Aber wir bleiben mal auf der hohen Flughöhe und suchen uns auch für das Keyword-Histogramm eine Überlagerung mit anderen Daten:

Hier überlagern wir das Keyword-Histogramm mit den jeweils zu den Keyword-Anzahlen gehörenden Wort-Mengen. Ganz offensichtlich haben längere Artikel im Durchschnitt auch mehr Keywords was durchaus einer gewissen Logik entspricht, wenn ein Thema breiter betrachtet wird oder z.B. die "Was war, was wird"-Artikel schlicht die Top-Themen einer ganzen Woche diskutieren.
Für heute können wir uns noch der Frage widmen, ob es auch bei dieser Betrachung Unterschiede bei den Autoren gibt:

Hier sind nun dediziert für einzelne Autoren deren Histogramme nebst WordCnts aufgetragen. Die Höhe der Balken ist hier weniger von Interesse, da Autoren mit weniger Artikeln natürlich auch in dieser Grafik kleinere Balken erzeugen. Auffällig -- und relevant -- ist jedoch wieder die Lage des Maximums sowie die Breite des Histogramms: Ganz offensichtlich haben die Autoren unterschiedliche Gepflogenheiten was die Vergabe von Keywords angeht; ein weiterer Faktor, der für ein Fingerprinting verwendet werden könnte.
Über Autoren lässt sich aus den Daten also eine Menge ableiten und die Datenbasis lässt noch weit mehr zu, als hier dargestellt. Im nächsten Teil geht es dann detaillierter um die Keywords, bevor wir uns schließlich der Analyse der Userkommentare widmen.